
Inside LangVoice: How We Built the Fastest Scalable AI Voice Generation Platform
When we set out to build LangVoice, we had one mission: make AI voice generation as fast as possible while ensuring unlimited scalability. Today, we're pulling back the curtain on our architecture to show how we achieve sub-10-second response times for even the longest texts.
The Challenge: Speed vs Scale
Traditional text-to-speech systems face a fundamental tradeoff: you can be fast for short texts, or you can handle long texts—but not both. Here's why:
- GPU Processing Time: AI voice generation is computationally intensive
- Sequential Processing: Most TTS systems process text start-to-finish
- Cold Starts: Cloud GPU infrastructure has warm-up delays
- Scaling Bottlenecks: Adding capacity doesn't always improve response time
We solved all of these challenges with our innovative architecture.
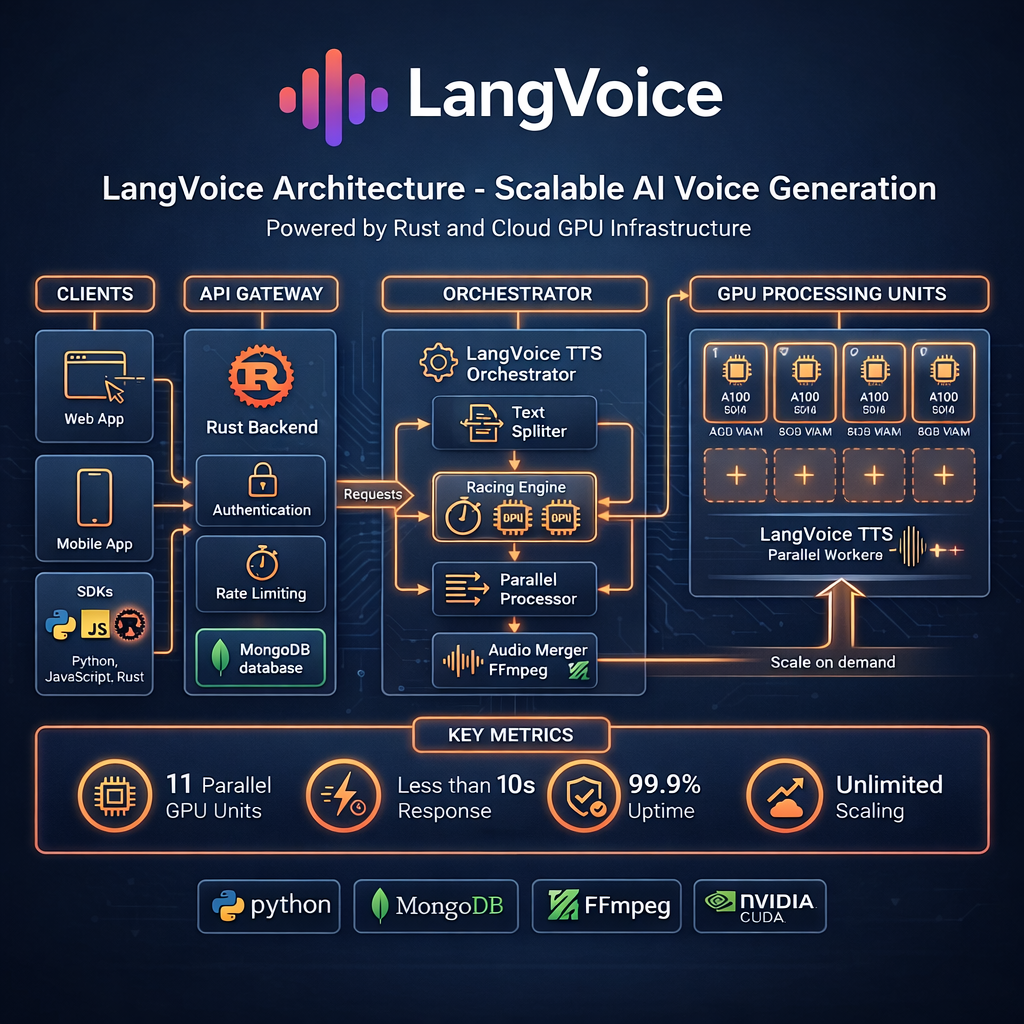
LangVoice Architecture: Built for Speed
1. Intelligent Text Orchestration
At the heart of LangVoice is our TTS Orchestrator—a sophisticated system that maximizes parallelization:
Text Splitter Our intelligent text splitter analyzes incoming text and divides it into optimal segments. Unlike naive character-based splitting, our system:
- Respects natural language boundaries (sentences, paragraphs)
- Optimizes segment sizes for GPU efficiency
- Balances load across available processing units
Racing Engine For short texts, we don't wait for a single GPU—we race multiple GPUs simultaneously. The first one to respond wins, and others are cancelled. This eliminates cold-start delays entirely.
Parallel Processor For longer texts, we distribute segments across multiple GPU Processing Units simultaneously. A 10,000-character text isn't processed 10x slower—it's processed in parallel.
2. GPU Processing Units
Our cloud infrastructure consists of multiple high-performance GPU Processing Units, each equipped with:
- 16GB+ VRAM for handling complex voice synthesis
- Optimized AI models fine-tuned for speed and quality
- Warm pools that eliminate cold-start delays
The key innovation: horizontal scaling. Need more capacity? We simply add more GPU units. Each unit operates independently, so scaling is linear.
3. Ultra-Fast Audio Assembly
Once all segments are generated, we use FFmpeg with a specialized concatenation approach that's 100x faster than traditional audio processing. We don't re-encode audio—we stream-combine it instantly.
The Numbers: Real Performance Metrics
| Text Length | Traditional TTS | LangVoice |
|---|---|---|
| 500 chars | ~5s | ~2s |
| 2,000 chars | ~20s | ~5s |
| 10,000 chars | ~100s | ~10s |
| 50,000 chars | ~500s | ~40s |
How do we achieve this?
- Parallel processing divides work across 11+ GPU units
- Racing mode eliminates cold-start latency
- Optimized models generate audio faster without sacrificing quality
- Smart caching reduces redundant computation
Auto-Scaling: Unlimited Capacity on Demand
Scale to Zero, Scale to Infinity
LangVoice is built on cloud-native infrastructure that scales automatically:
- During low traffic: Minimal resources active, keeping costs low
- During spike traffic: Additional GPU units spin up within seconds
- During extreme demand: Horizontal scaling adds capacity without limits
How Auto-Scaling Works
- Load Monitoring: Our orchestrator tracks request volume and queue depth
- Predictive Scaling: AI predicts demand spikes before they happen
- Instant Provisioning: New GPU units are pre-warmed and ready
- Load Balancing: Requests are distributed intelligently across units
The result: consistent sub-10-second response times regardless of how many users are hitting the API.
Reliability: 99.9% Uptime
Multi-Region Redundancy
Our infrastructure spans multiple cloud regions:
- Automatic failover if any region has issues
- No single point of failure in any component
- Health monitoring detects issues before they impact users
Graceful Degradation
Even under extreme conditions, LangVoice gracefully handles overload:
- Request queuing with intelligent prioritization
- Rate limiting protects system stability
- Fallback routing to backup GPU pools
For Developers: What This Means for You
Consistent API Performance
Whether you're generating a single sentence or an entire audiobook:
// Short text - fast response
const shortResponse = await langvoice.generate({
text: "Hello, world!", // ~1-2 seconds
voice: "heart"
});
// Long text - still fast response
const longResponse = await langvoice.generate({
text: longArticle, // 10,000 chars in ~10 seconds
voice: "heart"
});
No Timeout Worries
With response times consistently under 60 seconds even for very long texts, you don't need complex timeout handling or webhook-based architectures.
Predictable Pricing
Our pricing is based on characters processed—not processing time. Faster generation means better value.
The Future: What We're Building Next
Real-Time Streaming
We're working on streaming audio generation, where audio starts playing before generation completes. Imagine starting to hear your audiobook within 100ms of pressing play.
Edge Processing
By deploying smaller models to edge locations, we can reduce latency even further for common use cases.
Custom Voice Training
Soon, you'll be able to train custom voices with the same speed and scale benefits.
Conclusion
Building a fast, scalable TTS platform required rethinking every component from the ground up. By combining intelligent text orchestration, parallel GPU processing, and auto-scaling infrastructure, LangVoice delivers:
- ⚡ Sub-10-second generation for 10,000+ characters
- 📈 Unlimited scalability with horizontal GPU scaling
- 🎯 99.9% uptime with multi-region redundancy
- 💰 Cost efficiency through smart resource management
Ready to experience the fastest AI voice generation platform? Start for free or explore our API documentation.
Technical Stack: Our platform is built on Rust for performance-critical components, with Python for AI model serving, MongoDB for data persistence, NVIDIA CUDA for GPU acceleration, and FFmpeg for audio processing.
This post is part of our Engineering Blog series, where we share insights into how LangVoice is built.
Tags
Ready to Transform Your Text to Speech?
Try LangVoice free and experience the most natural AI voices for your content.
Try LangVoice Free

